- TIPS & TRICKS/
- Fraud Detection Using Machine Learning: Algorithm Comparison/


Fraud Detection Using Machine Learning: Algorithm Comparison
- TIPS & TRICKS/
- Fraud Detection Using Machine Learning: Algorithm Comparison/
Fraud Detection Using Machine Learning: Algorithm Comparison
Fraud has moved far beyond stolen cards and obvious scams. Modern attacks are fast, adaptive, and often coordinated: card‑not‑present fraud at online checkout, account takeover using harvested credentials, or mule networks laundering funds across many small transactions. These patterns shift daily, often exploiting tiny behavioural cues or device traces that are invisible to static rule sets. As transaction volumes and channels grow, purely rule‑based systems struggle to keep up without either missing fraud or overwhelming teams with false positives.
Machine learning (ML) is now central to fighting this arms race. It can sift millions of events in real time, capture subtle correlations, and evolve with new typologies. As one senior UK supervisor at the Financial Conduct Authority put it in the context of AI adoption, “firms that can explain and adapt their models quickly will be better placed to manage emerging financial crime risks”. Yet ML on its own is not a cure‑all. Fraud teams still need clear policies, expert investigators, and flexible rules to override, explain, or complement model decisions, especially during volatile trading periods.
This article is written for risk, fraud, and analytics teams in banks, fintechs, and payment providers. The focus is practical, not academic. You will not find code samples, formulas, or a dense survey of every algorithm. Instead, we will compare a core set of approaches you are most likely to encounter in production fraud systems: logistic regression, decision trees, random forests, gradient boosting, and deep learning.
By the end, you should have:
- A high‑level view of how these algorithms work in fraud contexts
- A sense of how they trade off accuracy, interpretability, and scalability
- Guidance on which techniques tend to suit different fraud types, data conditions, and operational constraints within a layered defence strategy.
Foundations: Fraud, data and what “good” looks like
What do we actually mean by “fraud detection using machine learning”?
Fraud detection with machine learning means using models that learn from past examples of fraud and genuine activity, then score new events in (near) real time. You feed the model labelled history – “fraud” or “not fraud” – and it learns patterns in the data that humans would struggle to spot quickly, such as subtle combinations of device, location, timing and behaviour. As the UK FCA notes in its research on machine learning in financial services, these approaches are particularly effective where there are high transaction volumes and rapidly evolving attack patterns.
In production, these models sit inside a wider decision engine. For each payment, login or account change, they output a risk score. That score then drives actions such as:
- Auto-approve low-risk activity.
- Step up checks (one-time passcodes, extra questions).
- Queue high-risk events for manual review or block outright.
Machine learning is one layer, not the whole defence. Effective programmes still rely on:
- Rules and policies for clear-cut situations and rapid changes.
- Investigators to review edge cases and refine strategy.
- Shared intelligence or consortium data to spot cross-organisation patterns.
- Strong processes and governance so decisions remain consistent and defensible.
Industry experience backs this layered approach: well-tuned models, combined with rules and human review, have been shown to detect the vast majority of fraud while materially reducing investigation effort and customer friction.
Types of financial fraud where ML is commonly applied
Common areas where machine learning adds value include:
Card and card-not-present fraud
Unauthorised use of cards in shops, online or in mobile apps, often involving compromised details and rapid testing across merchants. Banks and processors increasingly lean on real-time ML for this, with industry reports describing it as a “foundational” control for e-commerce and mobile payments.
Account takeover and identity theft
Criminals hijack online or mobile banking, email or wallets, often using stolen credentials, SIM swaps, or social engineering to pass security checks. Modern models combine login behaviour with device and network signals to distinguish genuine customers from impostors, a pattern highlighted in practice-focused discussions of maximising conversions while minimising fraud.
Application fraud (fake or synthetic customers)
Fraudsters create entirely fake identities, or blend real and fabricated data, to obtain credit, loans or devices they never intend to repay. Here, supervised ML and anomaly detection techniques help spot subtle inconsistencies across applications that traditional rule sets tend to miss.
Money laundering and mule networks
Layered transfers across accounts, countries and currencies to disguise criminal funds, frequently involving networks of “mule” accounts acting as pass-throughs. In anti-money laundering, regulators and industry bodies increasingly expect firms to use data-driven models to detect suspicious networks and transaction flows, not just simple threshold rules.
Each type has different patterns and time horizons, which in turn influence the algorithms, features and thresholds that work best.

The role of data: fuel and limits
Machine learning models are only as strong as the data behind them. For fraud work, useful signals typically include:
- Transaction and event data – amounts, merchants, channels, time of day, currency, payment method.
- Device and browser fingerprints – device IDs, operating system, browser, app version, language, jailbreak/root indicators.
- Location and network – IP address, country, distance from usual locations, VPN or proxy usage.
- Customer history – tenure, usual spend, typical merchants, login patterns, previous disputes.
- Behavioural signals – typing speed, swipes, click paths, session length, unusual navigation.
- External and consortium data – blacklists, risky devices or emails, shared fraud markers across institutions.
Labels are critical. “Confirmed fraud”, chargebacks, disputes and review outcomes tell the model what it should learn. Weak or noisy labelling quietly undermines every algorithm, no matter how advanced.
Fraud is not static. Attackers adapt, new products launch, and customer behaviour shifts. Features that were powerful last quarter can lose relevance. Models, features and thresholds must therefore be refreshed and monitored for drift, with challenger models tested before they replace incumbents.
Research on explainable AI in finance emphasises the importance of monitoring not just raw performance, but also whether the model’s key risk drivers remain stable and sensible over time.
Download our AI Data Analytics Tools Selector
 Download now
Download nowWhat “good” looks like: metrics and business impact
Headline accuracy can be misleading. In most portfolios, fraud is rare, so a model that simply predicts “not fraud” almost every time can look “accurate” on paper while missing nearly all real cases. More useful are:
- Precision – “Of the events we flagged as risky, how many were actually fraud?” High precision means fewer wasted reviews and fewer good customers declined.
- Recall (or detection rate)– “Of all the fraud that occurred, how much did we catch?” High recall means more prevented loss.
- False positives – genuine customers incorrectly flagged or blocked. These drive frustration, complaints and lost revenue.
From a business point of view, strong fraud detection looks like:
- Lower chargebacks and write-offs.
- Controlled manual review rates with better investigator productivity.
- Minimal friction for good customers and strong conversion at checkout or sign-up.
- Faster, more consistent investigations backed by clear rationales.
There is always a trade-off. The “best” model on a technical leaderboard might be too slow, too opaque, or too sensitive for real-world operations. In practice, teams often favour an approach that is slightly less predictive but faster to run, easier to explain to regulators and customers, and simpler to maintain alongside rules and human oversight.
As one recent analysis of explainable AI in finance puts it, “for fraud detection, tree-based ensembles plus post-hoc explanations frequently offer the most practical balance between raw accuracy and the ability to justify decisions to non-technical stakeholders.”
Why interpretability matters in fraud
In fraud, explainability is not a “nice to have” – it is a regulatory and operational requirement.
Regulators, auditors and internal model risk teams need to see why a transaction was declined or a customer was flagged. If they cannot trace a clear line from data to decision, they will push back on deployment or tighten controls around the model. The FCA’s work on machine learning in UK financial services highlights this explicitly, noting that firms must be able to “evidence and explain” automated decisions where customers are adversely affected.
Investigators also depend on transparent models. When a queue of alerts builds up, they must see in seconds which features drove the score to decide whether to close, escalate or request more information. If the logic is opaque, case handling slows and backlogs grow. As one global bank fraud lead put it, “if an investigator cannot restate the model’s reasoning in two sentences, it is not usable in production.”
Customer communication is another pressure. When a payment is blocked or an account is frozen, front-line teams need to explain the decision in plain language: “multiple high-value payments from a new device in a new country” is acceptable; “a complex model decided so” is not. Research on explainable AI in finance stresses that customer-facing rationales must be human-readable and linked to recognisable behaviours, not just technical model outputs.
Interpretable models help by:
- Making governance and audit easier.
- Speeding analyst triage and reducing manual review effort.
- Supporting clear, defensible reasons in customer interactions.
This is why logistic regression and decision trees remain central, even as more complex models become available and as firms experiment with higher-lift techniques within layered fraud strategies described in industry analyses of ML-based fraud prevention.
Logistic regression: the baseline model
Logistic regression turns a set of features about a transaction or customer into a risk score using a weighted sum. Each feature (for example, device tenure, transaction amount, IP distance from home address) gets a weight; the model combines them to estimate the probability of fraud. Its role as a workhorse for binary risk decisions is well documented in practitioner-focused overviews of ML in fraud and credit.
In many fraud settings, logistic regression is a strong baseline:
- Accuracy: When you have well-engineered features capturing known fraud signals, it can perform competitively and, importantly, produces well-calibrated probabilities. These probabilities plug neatly into thresholds, queues and pricing.
- Interpretability: Each coefficient directly reflects how a factor affects risk. For example, “high device velocity increases risk” or “long customer tenure reduces risk”. This mapping makes it easy to:
- Translate model behaviour into policies and written procedures.
- Justify thresholds to model risk committees.
- Generate simple narratives for investigators and customers, in line with transparency expectations highlighted in **regulatory discussions of AI and ML explainability**.
- Scalability and latency: Scoring is just a few arithmetic operations. This makes logistic regression ideal for very high-volume, low-latency flows such as card authorisations, instant payments and login checks.
It fits best when:
- Fraud patterns are relatively stable and well understood.
- You have rich, curated features from transaction histories, devices and behaviour.
- Governance, documentation and auditability are as important as raw lift.
- You need a benchmark to compare more complex models against, or a conservative backstop for production.
Its main drawback is flexibility. Logistic regression struggles with highly non-linear relationships or complex interactions unless these have been manually encoded as features. As fraudsters adapt and combinations of behaviours become more important than single signals, this can limit top-end accuracy, prompting many programmes to pair it with more flexible models or to deploy it as a stable reference point when validating tree-based or ensemble approaches described in explainable-AI guidance for financial institutions.
Decision trees: interpretable logic
Decision trees work as a sequence of yes/no questions on the data. Each split routes a transaction down a branch unil it reaches a leaf with a final decision or risk score. For instance: “Is the amount > £500?” → “Is the device new?” → “Is the IP foreign?” → flag or approve.
This structure gives them several advantages:
- Accuracy: Trees naturally capture simple non-linearities and interactions such as “high amount AND new device AND foreign IP”, which are common in fraud scenarios and often cited in industry case studies of ML fraud controls**.
- Interpretability: The path through the tree is easy to follow:
- Investigators can say, “this transaction was flagged because it was high value, on a new device, from a high-risk country”.
- Fraud teams used to rules engines find the logic familiar and can reason about changes quickly.
- Scalability: A single, moderately sized tree is very fast to score and straightforward to deploy in real-time systems or embedded in existing decision engines.
Decision trees are a good fit when:
- You need clear, auditable logic that can be adjusted at short notice.
- You are building hybrid designs where trees sit alongside handcrafted rules and thresholds.
- Operational teams want to “see the rules” rather than rely on abstract model parameters.
However, single trees have limits. If you grow them deep, they tend to overfit noisy fraud data; if you prune them aggressively, they may underfit and miss subtle patterns. On complex, high-dimensional data, they often cannot match the accuracy of more sophisticated ensembles, which is why forests and boosting are widely used.
Summary trade-offs for interpretable models
Logistic regression and decision trees offer different strengths but serve the same goal: fast, transparent fraud decisions that stand up to scrutiny.
- Accuracy: Logistic regression is strong when relationships are close to linear and features are carefully engineered. Decision trees do slightly better where key fraud signals come from clear cut-offs and interactions, but may plateau on very messy data.
- Interpretability: Both are highly transparent, just in different forms:
- Logistic regression gives a global view of how each factor shifts risk across the portfolio.
- Decision trees provide case-level stories via the path taken to a leaf.
- Scalability: Both score extremely fast and are easy to embed in real-time payment and login journeys. Logistic regression is often simpler to maintain across many channels; trees integrate naturally with rule-based platforms.
In practice, these models are essential tools where transparency, stability and governance are non-negotiable. Many programmes use them as:
- Primary models in highly regulated, high-volume environments.
- Benchmarks and safety nets against which more complex, less interpretable models are evaluated.
- Building blocks within layered architectures that combine rules, interpretable models and more advanced techniques, echoing the layered defences recommended in modern ML fraud-prevention frameworks.
Ensembles for tabular fraud: Random forests and gradient boosting
Why ensembles became the standard for many fraud teams
Tree ensembles combine many weak decision trees into a stronger overall model. Each tree captures a slightly different view of the data; taken together, they average out noise and sharpen the signal.
- This is a strong fit for transactional fraud data, which is typically:
- Tabular (amounts, merchant IDs, device details, locations, timestamps).
- Noisy and imbalanced (few frauds, many normal transactions).
- Full of non‑linear interactions (for example, “time of day” behaves differently by country, channel and device).
Compared with single trees or simple linear models, ensembles usually deliver a clear uplift in detection without sacrificing the low‑millisecond scoring needed for payment flows. Industry case studies suggest well‑tuned machine learning systems can detect a large majority of fraudulent events while materially reducing investigation time, especially when fed with rich transaction and device data and deployed as part of layered controls alongside rules and human review. That is why many payment and card fraud programmes now treat them as the default choice, wrapped in rules and human review rather than used in isolation.
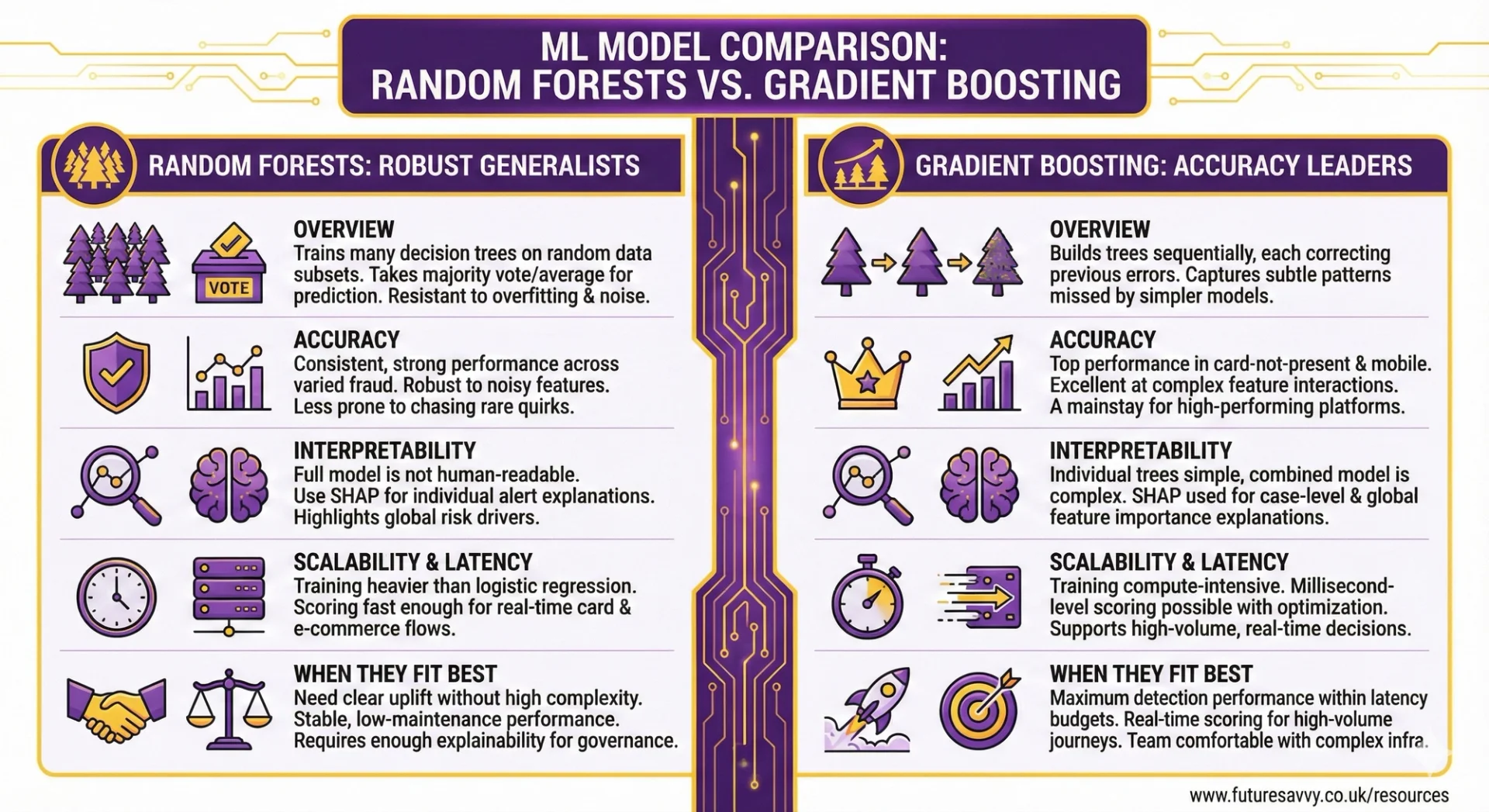
Random forests: robust generalists
Random forests train many decision trees on random subsets of data and features, then take a majority vote (or average) of their predictions. This randomness makes them resistant to overfitting and to messy feature sets.
As one senior fraud modeller at a UK bank put it, “random forests gave us a straightforward way to move beyond scorecards without blowing up our latency or our model‑risk process”.
Accuracy
- Consistently strong performance across varied fraud portfolios.
- Naturally robust to noisy or partially redundant features.
- Less prone to “chasing” rare quirks in historical data than single deep trees.
- Widely used in production fraud and credit models across banks and fintechs, where they often outperform logistic regression on complex, non‑linear data while remaining operationally stable.
Interpretability
- The full forest is too large to read tree‑by‑tree.
- Global feature importance helps highlight the main risk drivers (for example, device history, recent dispute behaviour, merchant risk).
- Post‑hoc tools such as SHAP are commonly used to explain individual approvals, declines, or alerts for investigators, and are now recognised in regulatory and policy discussions on explainable AI in finance as a pragmatic way to open up tree‑based models.
Scalability and latency
- Training is heavier than logistic regression, but manageable for most mid to large institutions.
- Scoring is typically fast enough for real‑time card and e‑commerce flows, especially when the forest size and depth are tuned with latency in mind.
- Experience from large payment gateways shows that even sizable forests can comfortably support real‑time decisions when implemented with basic optimisation.
When they fit best
Random forests work well when you need:
- A clear uplift over linear models, without jumping straight to the most complex options.
- Stable, low‑maintenance performance across products and regions.
- Enough explainability to satisfy governance, using standard post‑hoc tooling that risk and compliance teams increasingly see as established practice for tree‑based models.
Gradient boosting (XGBoost, LightGBM, CatBoost): accuracy leaders
Gradient boosting builds trees sequentially, with each new tree focusing on the mistakes of the previous ones. This “error‑correcting” process lets the model capture subtle patterns that simpler methods miss.
Accuracy
- Frequently achieve top performance on card‑not‑present, mobile and online payment fraud, and are now a mainstay of high‑performing fraud platforms in banks and fintechs.
- Excellent at modelling complex feature interactions and rare but high‑impact fraud patterns.
- Often selected as the primary model family in modern fraud stacks because they deliver strong detection while supporting real‑time decisions at scale.
Interpretability
- Individual trees are small and simple, but hundreds or thousands of them are not human‑readable as a whole.
- SHAP and similar methods are now standard for:Case‑level explanations (“unusual device and IP pattern increased the score”).
- Global views of which features matter most and how they influence risk.
- These global summaries help with fairness checks and with translating model behaviour into policy, aligning with guidance on balancing performance and transparency for machine learning in UK financial services.
Scalability and latency
- Training can be compute‑intensive, but modern libraries are heavily optimised and support distributed training.
- With careful engineering, boosted trees can deliver millisecond‑level scoring in high‑volume gateways and mobile apps.
- In practice, many large institutions now rely on gradient boosting as a core component of their fraud engines, combining it with rules and case management to control false positives and operational load.
When they fit best
Gradient boosting is usually the first choice when you need:
- Maximum detection performance within strict latency budgets.
- Real‑time scoring for e‑commerce, mobile and card‑not‑present journeys.
- A team comfortable operating more complex infrastructure and explainability tooling, similar to the set‑ups described in industry discussions of machine learning‑based fraud controls.
Managing explainability and governance for ensembles
Ensembles are not inherently transparent, so they rely on post‑hoc explainability rather than being self‑explanatory.
In practice, this means:
- Using SHAP (or similar) as a standard layer feeding investigator dashboards and case notes.
- Preparing simple narrative templates for customers and frontline staff, translating technical attributions into plain language (for example, “unusual location and device for this account”).
- Working with compliance, legal and model risk functions to agree which explanation types are required for regulators, internal audits, and customer communications. Recent work on explainable AI in finance highlights fraud and AML as areas where this dialogue is particularly important.
For many payment and card fraud programmes, tree ensembles hit a useful balance:
- High accuracy on noisy, evolving transactional data.
- Latency compatible with real‑time decisions.
- Manageable explainability and governance when paired with robust XAI and clear documentation.
Used in a layered set‑up alongside rules and human review, they often provide the best accuracy–complexity trade‑off for modern fraud teams.
What we mean by “deep learning” in fraud
In this context, “deep learning” usually means neural networks that can handle richer, more complex data than standard tabular models:
- Sequential data – models such as recurrent or transformer-based networks analyse transaction streams, login sequences, and behavioural biometrics (typing rhythm, swipe patterns) to spot subtle changes over time.
- Network and graph data – graph neural networks and related architectures model relationships between accounts, devices, merchants and IPs, helping to expose mule networks, layering in AML, and shared infrastructure across “clean” and “dirty” entities.
- Unstructured signals – text models extract risk cues from claims notes, dispute narratives or application forms; in some niches, image, document and voice models help validate identity or detect forged documents.
The core idea is that these models learn patterns directly from the raw structure of the data, rather than relying solely on hand-crafted features.
Strengths of deep learning for fraud
Deep learning is most attractive where patterns are complex, high dimensional, and spread over time or across entities. Industry experience suggests that, when applied in the right context, it can materially increase fraud capture without overwhelming operations, aligning with broader evidence that machine learning can detect a large share of fraud while cutting investigation effort.
- Richer pattern discovery – it can capture higher-order, long-range interactions that boosted trees or forests may miss, such as slow-build mule rings or multi-step money flows. This is particularly relevant in environments where fraud patterns evolve quickly and adversaries probe for weaknesses using their own data-driven models.
- Entity and relationship focus – for AML and networked fraud, it can treat the whole graph of customers, devices and accounts as the object of interest, not just single transactions. This mirrors how advanced transaction monitoring systems increasingly model webs of counterparties rather than isolated events.
- Automatic feature learning – for sequences, graphs and text, the model can learn useful representations directly, reducing the amount of manual feature engineering needed. In practice, this allows teams to bring in richer telemetry (behavioural biometrics, device intelligence, clickstreams) without first reducing everything to hand-crafted summary fields.
Used well, this can lift detection rates on sophisticated schemes without exploding false positives, especially in AML-style monitoring and advanced account takeover scenarios.
Challenges: explainability, scale and fit-for-purpose use
The power of deep learning comes with trade-offs that matter greatly in regulated finance. As one senior regulator put it, “a model can be complex, but its effect on customers and markets must still be clearly understood and governed”.
Explainability
Neural networks are rarely transparent by design. Investigators and regulators typically need:
- Post-hoc tools (for example, feature attributions or counterfactual-style explanations) to show which behaviours or relationships drove a score, consistent with explainable AI practices described in work such as Explainable AI in Finance from the CFA Institute Research and Policy Center.
- Visualisations for network models that highlight suspicious paths or clusters rather than opaque node embeddings.
These explanations are often harder to trust and standardise than the path-based logic of trees or the coefficients of regression, and model risk teams may need extra controls to evidence fairness and robustness.
Scalability and latency
- Training can be expensive and slow, often requiring GPUs or other accelerators.
- Real-time scoring is feasible but needs careful optimisation; deep graph models in particular can threaten millisecond latency budgets at checkout or login, especially at large payment or e-commerce volumes.
Supervisors such as the UK Financial Conduct Authority have noted in their work on machine learning in financial services that these infrastructure demands can be a barrier for smaller firms and a source of operational risk for larger ones.
Governance and regulation
- Model approval, periodic review and audit may be slower due to complexity and lower intuitive interpretability. Governance frameworks often need to spell out how deep models sit alongside more traditional scorecards and rules.
- There is an added risk of proxy bias, and some explanation outputs can inadvertently expose sensitive links or encourage gaming, which must be managed through policy and tooling. This aligns with broader regulatory expectations that AI-driven decisions be explainable, non-discriminatory, and subject to effective oversight.
When deep learning is worth the investment
Deep learning is rarely the first choice for basic card-not-present or login fraud where gradient boosting or random forests usually hit a strong accuracy–latency–explainability balance. It becomes compelling when:
Use cases involve:
- AML and transaction monitoring over long time horizons with many intermediaries.
- Networked fraud across devices, identities and institutions, where understanding relationships and contagion effects is crucial.
- Behavioural biometrics and device intelligence that generate rich, high-frequency signals.
Preconditions are in place:
- Mature data engineering, including graph construction, sequence pipelines and unstructured data handling, and access to high-quality internal and external data sources of the sort highlighted in industry analyses of machine learning for fraud and conversions
- Robust MLOps and model risk frameworks, including systematic use of explainability tools and clear policies for how investigators and compliance teams consume explanations.
Without these, deep learning often adds complexity faster than it adds value, and simpler ensemble models paired with explainability techniques may remain the more pragmatic choice.
Hybrid and layered designs
In practice, the most effective fraud setups combine models rather than betting on a single deep architecture. This layered approach is consistent with guidance from both regulators and industry bodies that position AI as one component within a broader control framework.
Rules + ML
Business rules remain essential for hard policy constraints (sanctions hits, obvious red flags) and emergency brakes, with ML models providing nuanced ranking and thresholding within those guardrails.
Combining models
- A tree-based ensemble (for example, gradient boosting) often acts as the primary, low-latency scorer on tabular features.
- Deep sequence or graph models contribute additional risk signals or specialist scores for complex patterns, particularly in AML and networked fraud.
- Unsupervised methods such as anomaly detection help surface emerging behaviours that supervised models have not yet seen, supporting faster response to novel scams.
Human-in-the-loop
High-risk or novel cases should still go to investigators, whose feedback is looped back into re-training and threshold tuning. This keeps complex models anchored to operational reality and reflects wider best practice on “evaluative AI”, where human experts remain central to final decisions.
A useful rule of thumb:
- Start with the simplest model that meets your detection, latency and explanation requirements.
- Add deep or hybrid components only where the data and use case clearly demand it, and where your organisation can support the extra operational and governance burden.
Recap of the main comparison points
Across the spectrum of algorithms, the trade-offs are clear:
- Logistic regression and decision trees give fast, stable baselines that are easy to explain and govern. They work well when features are well engineered and policies must be fully transparent, which is why they remain common in regulated areas such as credit and fraud scoring across major banks and card schemes.
- Random forests and gradient boosting usually deliver the strongest accuracy–latency balance for payment and account fraud, especially when paired with explanation tools such as SHAP and similar feature-attribution methods now widely discussed in explainable AI guidance for finance.
- Deep learning and graph-based approaches shine on complex behaviour, sequences and networks, but demand more effort in governance, monitoring, and post-hoc explanation to satisfy the kinds of transparency expectations highlighted by regulators and policy bodies.
In practice, many successful fraud stacks blend these: simple models for guardrails and policy checks, tree ensembles for core scoring, and deep or graph models for advanced detection. As one senior fraud lead quoted by Finextra puts it, “the winning approach is rarely one model, it is an ecosystem where each model plays a clearly defined role”.
Practical selection guidelines
For most card and e‑commerce fraud teams, the pragmatic route is:
- Use gradient boosting or random forests as your primary model, engineered for low-latency scoring.
- Maintain a logistic regression benchmark and backstop to validate performance and support simpler explanations.
Where regulation and explainability dominate (for example, consumer lending or highly scrutinised payment flows), prioritise logistic regression or shallow trees enriched with strong features, even if this means sacrificing a small amount of peak accuracy. This aligns with the direction of travel in explainable AI work from organisations such as the CFA Institute’s research centre and the UK’s Financial Conduct Authority, which both emphasise clarity of rationale alongside raw performance.
For networked financial crime such as money mule rings or AML typologies, consider deep or graph models to surface higher-order patterns. Layer these with simpler models and robust explainability so investigators, compliance and auditors can still understand why alerts are raised and how they link back to specific behaviours or relationships.
In summary, anchor your choice to:
- Fraud type and data complexity
- Latency and volume constraints
- Required level of explainability and auditability
Algorithm choice is only one pillar of an effective fraud strategy. Outcomes are driven just as much by:
- data coverage and label quality
- thoughtful feature engineering and drift monitoring
- clear governance, documentation and access control
Continuous experimentation matters: run champion–challenger tests, revisit thresholds, and track metrics that reflect both fraud loss and customer experience, not just model accuracy. Industry experience summarised by Finextra suggests that teams who treat this as an ongoing optimisation problem can materially improve both fraud capture and legitimate conversion rates over time.
The most resilient fraud teams treat model selection as an ongoing, evidence-based process. Start with the simplest approach that meets your needs, integrate it into a layered defence with rules and human oversight, and evolve your toolbox as fraud patterns, data and regulatory expectations change, in line with the broader move towards explainable, accountable AI in financial services.
Frequently Asked Questions (FAQ)
Prompting, verification, workflow design, automation, and responsible AI use.
No. These skills apply across functions, from admin and marketing to finance and operations.
Clear examples of how you used AI to save time, improve quality, or support better decisions.
Begin with your current tasks, test AI on repeat work, and track the results.
Related Articles
 Tips & Tricks
Tips & TricksAI Invoice Processing: The End of Manual Entry
Manual invoice processing is slow, error-prone, and limits visibility into cash going out the door. AI invoice processing automates data capture, PO matching, approval routing, and fraud/duplicate checks so AP teams can focus on exceptions instead of typing and chasing. The article explains how the technology works day-to-day, what features and KPIs matter most, and a practical roadmap to pilot, roll out, and prove ROI quickly.
 Tips & Tricks
Tips & TricksTop AI Asset Management Platforms Reviewed
AI asset management patforms are moving into mainstream use as firms face fee pressure, tighter regulation, and the need to scale investment workflows with clear audit trails. The article compares platforms as products - focusing on real-world portfolio construction and rebalancing, transparent risk analytics, scalable personalisation and suitability, integrations, deployment options, economics, and governance.
 Tips & Tricks
Tips & TricksData Analytics and AI: From Reporting to Predicting
Finance teams are stuck in static, backward-looking month-end packs that arrive too late to support fast decisions. By layering AI-enabled analytics on top of existing ERP/EPM, BI, and Excel - grounded in governed, “investment-grade” data - teams can automate reporting narratives, move to rolling forecasts, and add prescriptive recommendations directly in the flow of work. The winning approach is incremental: start with low-risk automation, build trust through explainability and audit trails, keep humans accountable, and scale what works via repeatable workflows.
