- TIPS & TRICKS/
- How to Conduct an AI Proficiency Assessment/


How to Conduct an AI Proficiency Assessment
- TIPS & TRICKS/
- How to Conduct an AI Proficiency Assessment/
How to Conduct an AI Proficiency Assessment
AI is no longer a nice-to-have add‑on. In many knowledge roles, it has become a baseline expectation, shaping how work is planned, executed, and reviewed. Large employers now talk about AI fluency in the same breath as core digital skills: BlackRock’s global head of talent acquisition, for example, describes strong candidates as “digitally native and comfortable with various AI tools”, with a basic ability to question AI outputs rather than accept them at face value.
The real shift is subtle but profound: the most valuable employees are not the ones who can do everything themselves, but those who can orchestrate AI tools - breaking down problems, prompting effectively, and stress‑testing machine‑generated answers before anything reaches a client or stakeholder.
Traditional assessment methods are struggling to keep up. Tests that ban AI, rely on rote questions, or measure only solo execution no longer predict real performance. Many can even be completed by AI itself, making it hard to distinguish genuine capability from clever tool use.
Forward‑looking organisations are starting to respond by reframing what they measure. Financial‑sector bodies such as the CFA Institute emphasise explicit skills taxonomies and multi‑level proficiency frameworks, so AI capability can be tied to real roles and outcomes rather than generic “AI literacy” checklists.
This article shows you how to design an AI proficiency assessment that is:
- Practical and grounded in real work scenarios
- Fair, transparent, and resistant to simple gaming
- Aligned with specific roles, not generic “AI trivia”
It is written for HR professionals, hiring managers, L&D leaders, and team leads who need to evaluate AI skills reliably and at scale, without losing sight of human judgement, ethics, and communication.
Clarify What You Mean by ‘AI Proficiency’
Before you can assess AI skills, you need a clear, shared definition. Vague labels like “AI-native”, “AI savvy” or “AI literate” sound appealing, but they are too fuzzy to assess fairly or to link to performance or development. They blur together tool familiarity, technical depth, and judgement, and they tend to age quickly as specific tools change. As the CFA Institute notes in its work on skills taxonomies for the financial industry, organisations that skip clear definitions end up with “inconsistency and low comparability” in how they talk about skills and proficiencies across roles.
A more useful approach is to define AI proficiency as a blend of three pillars you can actually observe:
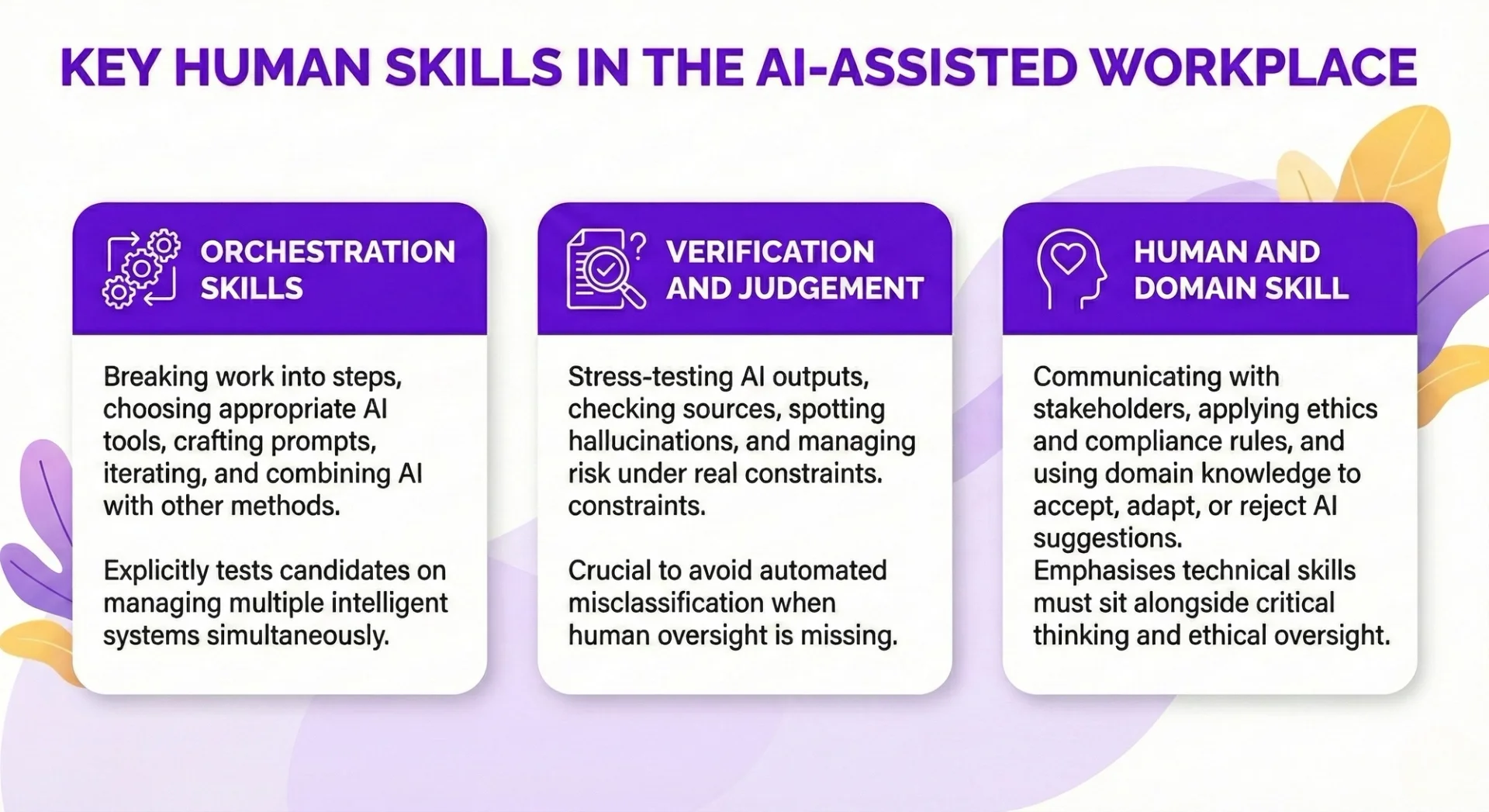
Framing proficiency as “orchestrating AI” rather than “knowing AI” matches how work actually happens: people rarely build models from scratch, but they increasingly direct and supervise them. This also shifts attention away from one-off technical tricks towards repeatable behaviours you can train and measure.
It is the same distinction BlackRock’s head of talent acquisition draws when he looks for people who are “curious, have a questioning mindset, and are willing to not just trust what the model puts out there, but also make sure we’re continuing to pressure test that”.
In practice, you are looking for people who can:
- Turn messy problems into AI-ready tasks.
- Use AI to generate options, then refine and integrate outputs.
- Explain and defend AI-assisted decisions to non-experts.
This clearer model becomes the backbone of your assessment. It lets you design realistic tasks, observe process as well as outcomes, and avoid over‑valuing either raw speed or tool‑specific hacks. It also aligns your hiring and development with emerging, domain‑specific frameworks for evaluating AI use in real workflows, rather than with generic notions of being “good with AI”.
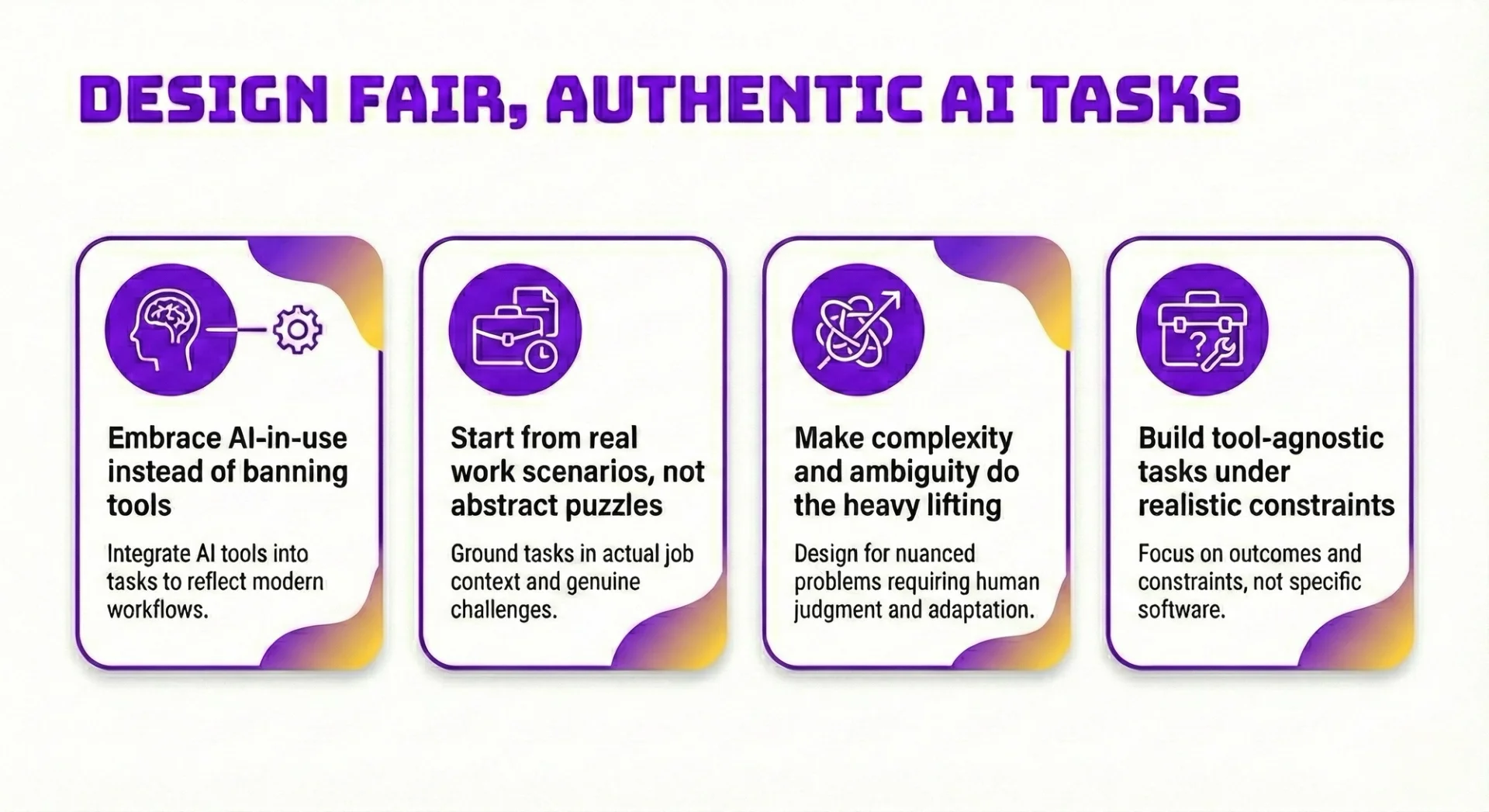
Design Fair, Authentic AI Tasks
Embrace AI-in-use instead of banning tools
If your assessment bans AI, you are testing how people work in a world that no longer exists. In most knowledge roles, AI is now part of day-to-day execution, so “no tools allowed” tasks reward memorisation and speed typing rather than orchestration and judgement.
BlackRock’s global head of talent acquisition, for example, explicitly looks for candidates who are “digitally native and comfortable with various AI tools”, with a “questioning mindset” rather than blind trust in model outputs, because that is how real work now gets done in the firm’s AI-enabled environment.
Instead, design tasks that explicitly allow AI under clear rules. Make it transparent which tools are available, what data can be used, and how activity will be monitored. This lets you evaluate how candidates:
- Frame problems for AI and refine prompts.
- Iterate, compare options, and select the best outputs.
- Verify accuracy and apply domain constraints.
This approach mirrors how firms like Shopify are beginning to bake “reflexive” AI usage into performance reviews and resourcing decisions, treating AI capability as a baseline expectation rather than a bonus skill. It also sidesteps the growing evidence that AI-writing detectors are unreliable and biased, especially for non-native speakers, as highlighted by a Stanford study on detector misclassification of human-written essays.
Be wary of ultra-simple tasks. If a single generic prompt produces a complete answer, you are mostly assessing model capability, not human skill. A valid task forces the candidate to go beyond “ask once, copy-paste”, showing how they direct, critique, and adapt AI output. Emerging AI-assisted assessments in technical hiring already follow this pattern: platforms such as CodeSignal are shifting from simplified coding questions to complex, AI-enabled scenarios that explicitly measure how well candidates collaborate with AI, not whether the AI can solve the problem unaided.
Start from real work scenarios, not abstract puzzles
Anchor your assessment in situations people actually face in your organisation: rewriting a client email, summarising a technical report for executives, or sketching an analysis plan from messy notes. This surfaces the skills you really need, not puzzle-solving tricks.
In finance, for instance, guidance from the CFA Institute on large language models stresses that meaningful evaluation comes from task-specific scenarios – like sentiment analysis, numerical reasoning over earnings reports, or drafting risk disclosures – that mirror real workflows rather than generic NLP benchmarks.
For each scenario, build in three ingredients:
- Task decomposition – The brief should be slightly messy so candidates must clarify goals, identify stakeholders, and break work into sensible stages.
- Tool selection – Require explicit choices: which AI tool (if any), which datasets or dashboards, and when to step away from AI altogether.
- Human oversight – Layer in brand tone, compliance rules, or domain nuances so that blind trust in AI will fail. Candidates must adapt and correct the output, not just accept it.
Make complexity and ambiguity do the heavy lifting
As models get stronger, complexity and ambiguity are what reveal human proficiency. Design tasks that:
- Chain multiple phases (e.g. research → synthesis → communication).
- Expose trade-offs such as speed versus accuracy, or client demands versus internal policies.
- Include gaps, contradictions, or noisy information that must be queried or challenged.
Ambiguous elements force candidates to ask clarifying questions, note assumptions, and structure their approach. You then see who can manage uncertainty, pressure-test AI suggestions, and still produce a defensible outcome. This aligns with how leading assessment providers are redefining skills tests in the AI age: multi-step, realistic scenarios are used to observe problem-framing, orchestration of tools, and critical evaluation of AI-generated options, not just final answers.
Build tool-agnostic tasks under realistic constraints
Your goal is to assess transferable AI skills, not mastery of one vendor’s interface. Frame tasks so they work across different models and deployments, while mirroring your real constraints:
- Data privacy – Prohibit pasting sensitive data into public tools; see how candidates adapt workflows. In regulated sectors, practical guides for LLM use emphasise privacy-preserving architectures and on-premise or private-cloud deployments to enable realistic yet compliant testing.
- Internal knowledge – Require citing internal documents or repositories, not just web search.
- Regulation and ethics– Embed rules that must be observed and ask candidates to justify how they upheld them. Skills frameworks in finance increasingly treat ethical judgement, explainability, and oversight as core competencies alongside technical AI use, and your assessments should do the same.
- Designing this way means you can switch between open and closed models, or move from cloud to on-prem, without rewriting the whole assessment - your tasks still test orchestration, verification, and compliant use of AI, whatever stack you run.
Capture Process, Not Just Answers
Why process evidence matters
If you only mark the final output, AI can mask big gaps in human skill. A candidate might submit a flawless report or working script that was mostly generated in one click, with little understanding of how or why it works.
Process evidence shows whether people can actually orchestrate AI:
- How they break down the task and frame prompts.
- How they adapt to weak or wrong answers.
- How they test, verify, and refine the result.
- How they learn something they could reuse next time.
These behaviours are where real value lies. In modern roles, the differentiator is less “can you produce this artefact?” and more “can you direct AI safely and intelligently under real constraints?”. You only see that through the process.
As BlackRock’s global head of talent acquisition notes, they now look for people who can “not just trust what the model puts out there, but also make sure we’re continuing to pressure test that”, making the candidate’s visible decision-making around AI at least as important as the final deliverable itself.
Practical ways to capture process
You do not need complex surveillance to understand how someone works with AI. Focus on lightweight signals that show their decision-making:
- Prompt and query logs– record prompts, follow-ups, and tool switches to reveal task decomposition and prompt quality.
- Version history – capture drafts, edits, and where candidates overrode or reshaped AI output.
- Time and iteration patterns – see whether they explore alternatives, backtrack, and test changes rather than copy-pasting the first answer.
- Short reflective prompts – at submission, ask for a brief explanation of what they did and why.
Make it clear this is about learning and fairness, not catching people out. When everyone knows that process counts, candidates are incentivised to work transparently and to develop good habits, not to hide AI use. This aligns with emerging skills frameworks in sectors like financial services, where process evidence and behavioural traces are increasingly used to build richer, more objective skill profiles rather than relying on static end products alone.
Avoid naïve AI detection tools
Text-style “AI detectors” that rely on perplexity or similar heuristics are unreliable and often unfair. They regularly mislabel fluent but simple writing - such as that from non-native speakers—as machine-generated, and can miss sophisticated AI-assisted text.
A Stanford-led study, for example, found that several popular detectors wrongly flagged more than half of genuine exam essays by non-native English writers as AI-written, with one tool misclassifying around 98% of them.
Do not use these tools as proof of cheating or as a proxy for ability. They:
- Create inequitable false positives.
- Offer no insight into how someone actually worked.
- Are easy to game with minor text edits.
Process-aware methods are both more ethical and more accurate. By observing how work is produced, you establish authorship and skill without guessing from surface style, which is why leading assessment providers are shifting towards activity-based and AI-assisted testing that measures how candidates solve problems step by step rather than what their prose “looks like”.
What to look for in strong AI use
When you review process data, look for observable, repeatable behaviours:
- Clear, specific prompts that state goals, constraints, audience, and format.
- Iteration: purposeful re-prompting, testing alternatives, and refining based on results.
- Verification: cross-checking facts, running tests, comparing against trusted sources, or adding domain-specific safeguards.
- Risk awareness: flagging uncertainty, likely hallucinations, or missing data and explaining how they handled these.
To make this scorable, build in 1–2 structured reflection prompts such as:
- “How did you verify this output?”
- “What would you do differently if this were a live client case?”
Short, consistent questions like these turn raw activity logs into clear evidence of AI orchestration, judgement, and readiness for real work. They also mirror how more mature skills taxonomies describe AI proficiency: not just in terms of tool operation, but in terms of interpretation, oversight, and the ability to explain and justify AI-supported decisions within real organisational constraints.
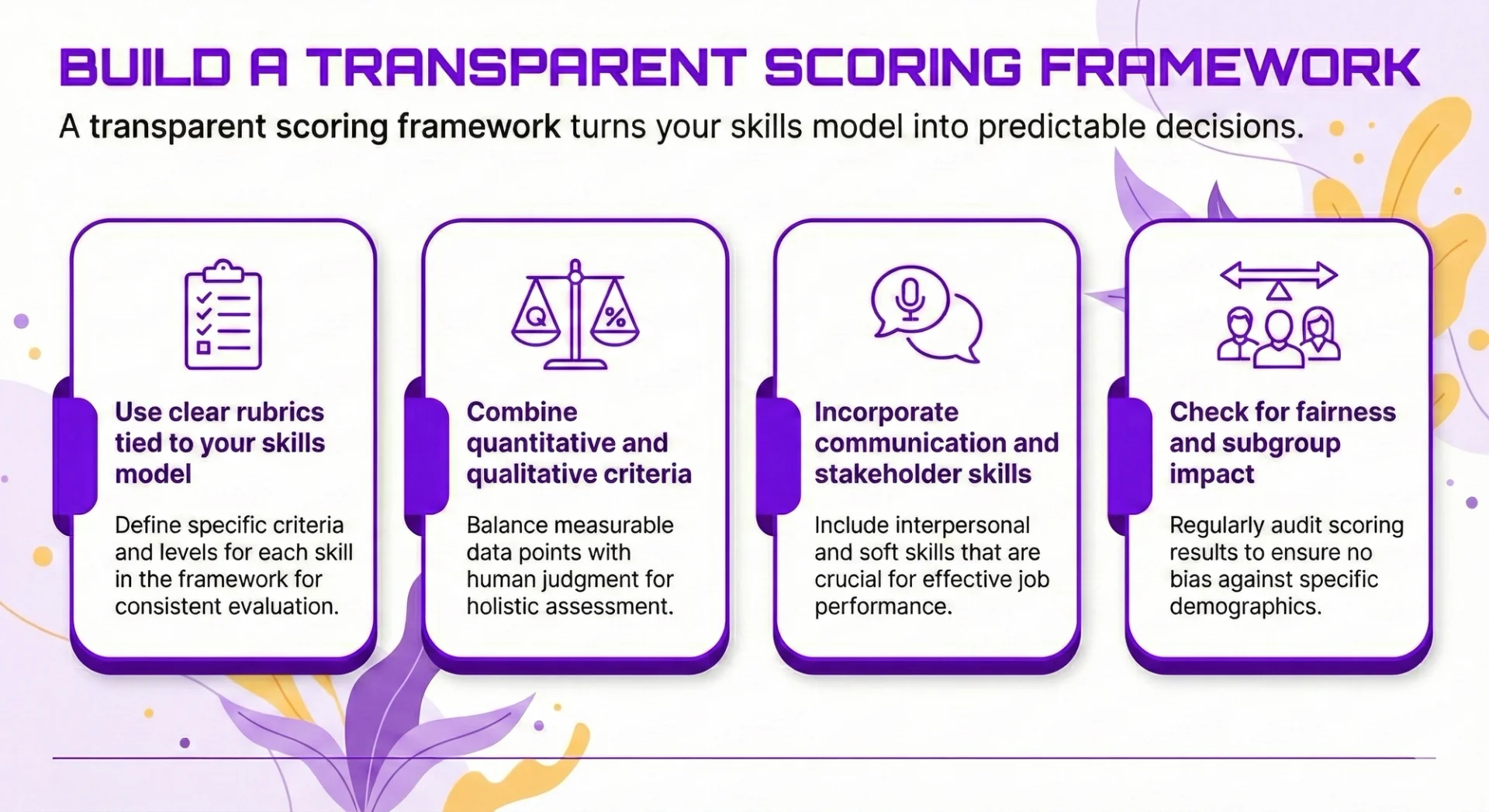
Build a Transparent Scoring Framework
A transparent scoring framework turns your skills model into predictable decisions. Candidates should be able to see how orchestration, verification, and human skills are judged, and managers should be able to explain scores without hand‑waving. As Claire Tunley of the Financial Services Skills Commission puts it, “the taxonomy is a library, and the architecture is how you structure your workforce” – your scoring framework is where that structure becomes visible and testable in practice.
Use clear rubrics tied to your skills model
Start by mapping your rubric directly to your AI skills taxonomy (for example: orchestration, verification, domain/human skills). For each dimension, define three bands with observable behaviours:
- Entry-level – can follow simple instructions and use basic prompts, but needs guidance to verify outputs or handle risk.
- Practitioner – decomposes tasks, iterates with tools, and routinely checks outputs against data, policies, or domain constraints.
- Advanced – anticipates failure modes, chooses tools strategically, and designs robust checks and controls for others.
This aligns with emerging skills architectures in sectors like financial services, where organisations are being pushed to define clear proficiency levels rather than rely on job titles or vague competency labels.
Make descriptors concrete rather than vague. For instance:
- “Identifies at least two plausible risks in using this output in production.”
- “Runs and documents at least one independent check on AI-generated data.”
- “Adapts prompts based on feedback from the AI and stakeholder constraints.”
Avoid generic labels like “good” or “poor”. If two reviewers cannot apply the rubric in the same way, refine it until they can. Some AI-first employers are already moving in this direction by making “reflexive” AI use and verification a visible dimension in performance and promotion decisions, not an informal expectation.
Combine quantitative and qualitative criteria
A credible framework blends numbers with judgement. Useful quantitative signals include:
- Accuracy against a gold standard or worked example.
- Time to reach a workable solution under realistic constraints.
- Number and effectiveness of iterations (not just fewer = better).
In highly regulated domains, this mirrors how LLMs themselves are evaluated against task‑specific benchmarks and gold‑standard datasets, rather than generic scores, to evidence reliability and fitness for purpose.
Pair these with qualitative criteria:
- Clarity and structure of reasoning and prompt strategy.
- Quality of communication artefacts (emails, summaries, slide notes).
- Evidence of ethical and compliance awareness, including when candidates choose not to use AI.
Weight process safety and reasoning at least as much as raw speed. A fast but unverified answer should never outscore a slower, well‑governed approach in risk‑sensitive roles. Large employers are explicitly prioritising this blend of curiosity, critical thinking, and challenge of AI outputs over narrow technical speed when they hire.
Incorporate communication and stakeholder skills
AI proficiency is not only about getting a result; it is about explaining and defending AI‑assisted work. Build in short add‑on tasks, such as:
- Writing an executive summary for a non‑technical stakeholder.
- Recording or presenting a brief rationale for a recommendation. Responding to a challenge about data sources, assumptions, or risks.
These tasks surface soft skills that matter in practice:
- Clarity and concision when translating technical details.
- Confidence without overclaiming certainty.
- Humility about model limits and willingness to adjust when challenged.
This is increasingly reflected in modern skills frameworks, which treat explanation, oversight, and ethical judgement as core AI‑era competencies rather than “nice to haves” attached to technical skills. Score these explicitly rather than treating them as “nice to have”. In many organisations, this is where real value and risk sit.
Check for fairness and subgroup impact
Before rolling out at scale, run basic fairness checks on your scoring framework:
- Review task and rubric language for unnecessary jargon or cultural references.
- Pilot with different groups (for example, non‑native speakers, career changers, mixed seniority) and compare outcomes.
- Flag items where one group consistently underperforms without a clear, role‑relevant explanation.
Avoid shortcuts such as text‑style or perplexity‑based “AI detection” to police integrity; these can penalise particular language backgrounds or writing styles. Research from Stanford, reported by Business Insider, has shown that popular AI‑writing detectors misclassify a majority of essays by non‑native English speakers as machine‑generated, while treating native‑speaker work much more leniently. Instead, rely on process evidence (prompt history, version diffs, reasoning notes).
A fair, explainable scoring system builds trust:
- Candidates understand what “good” looks like and how to improve.
- Hiring managers and HR can defend decisions under scrutiny.
- The organisation can scale AI assessments without embedding hidden bias.
Put Your AI Proficiency Assessment into Practice
Decide where the assessment fits in your talent lifecycle
Start by choosing one or two concrete use-cases, not “everything at once”. AI orchestration is becoming a baseline expectation, so your assessment should sit where it will actually influence decisions:
Hiring
Use role-specific, AI-in-use tasks to compare candidates against a clear standard: can they decompose a problem, prompt effectively, and verify outputs under realistic constraints? Employers like BlackRock already treat this as a hygiene factor, looking for people who are “digitally native and comfortable with various AI tools” rather than AI specialists in every role, and probing how candidates question AI outputs rather than simply accept them.
Promotion and performance
Distinguish between someone who can use AI for their own work and someone ready to manage AI-enabled workflows and coach others, including risk checks and communication. Shopify, for example, has made “reflexive AI usage” an explicit performance expectation and is weaving AI questions into peer and manager reviews, so that fluency with AI tools is assessed alongside traditional indicators of impact and growth.
L&D and workforce planning
Diagnose strengths and gaps (e.g. prompt design vs verification vs domain judgement) so you can target training and identify which teams are ready for more advanced AI responsibilities. In regulated sectors, guidance from bodies such as the CFA Institute on skills taxonomies and task-specific AI evaluation in finance underlines the need to anchor AI skills in clear role architectures and to revisit them as tools and markets change.
Treat AI proficiency like digital literacy: a requirement to participate, not a specialist add-on. As one talent leader put it, AI capability is becoming “a threshold competency” rather than a bonus.
Pilot, learn, and refine
Run a small pilot in one team or role before scaling. Build quick feedback loops:
- From participants: clarity of instructions, perceived fairness, cognitive load.
- From assessors: ease of scoring, consistency of judgements, usefulness of insights.
Use early data to:
- Adjust difficulty and time limits so tasks require orchestration and critical thinking without becoming endurance tests. Emerging AI-assisted assessments in coding, for example, use realistic, messy scenarios specifically to reveal how candidates collaborate with AI rather than whether they can solve a toy problem in 30 minutes.
- Simplify interfaces and guidance to minimise noise unrelated to AI skill.
- Tighten rubrics where scoring varies, especially around verification, ethical judgement, and communication quality. Be particularly cautious about over-relying on automated detectors: research reported by *Business Insider* has shown that common AI-writing detectors misclassify a high proportion of essays by non-native English speakers as AI-generated, highlighting the risk of building biased or invalid inferences into your scoring.
Turn results into action, not just scores
Scores are only useful if they drive decisions:
Individual
Feed results into development plans (e.g. more practice critiquing AI outputs; training on domain-specific risk and compliance). Work on skill assessments in the AI age suggests treating AI as an “extra brain in the room” to help design richer practice tasks and personalised feedback, while keeping humans in charge of high-stakes judgements.
Team
Surface patterns by role, location, or seniority to prioritise coaching, tooling, and support.
Organisation
Identify where AI can realistically deliver value now, where guardrails need strengthening, and where capability must grow before scaling use. This aligns with broader workforce architecture work that links skills frameworks directly to strategy, so assessment data feeds into hiring, reskilling, and succession planning rather than sitting in isolation.
Revisit and recalibrate the assessment periodically. As tools, roles, and regulations evolve, your definition and measurement of “proficient” must evolve too, just as leading financial and technology organisations are refreshing their AI skills taxonomies and benchmarks on an ongoing basis.
Thoughtful AI proficiency assessment is ultimately about how people orchestrate and govern AI in real work, not whether they can out‑perform the tools. It must be rooted in the context of your organisation, your roles, and the risks and opportunities AI creates.
As BlackRock’s global head of talent acquisition recently put it, employers now want people who are “curious, have a questioning mindset, and are willing to not just trust what the model puts out there, but also make sure we’re continuing to pressure test that” – a description that goes well beyond narrow tool usage and into everyday judgement and oversight.
A robust approach rests on five practical steps:
- Define what AI proficiency means for each role, using a clear, role‑aligned skills framework grounded in an explicit skills taxonomy and architecture, as advocated by the CFA Institute
- Design authentic, AI‑in‑use tasks that reflect real workflows and constraints, similar to how some technical assessments now focus on candidates orchestrating AI within complex, realistic scenarios rather than solving toy problems in isolation.
- Capture and evaluate the process, not just the final output, including how people prompt, verify, and adapt. This is especially important given evidence that seemingly “objective” automation, such as AI‑writing detectors, can systematically misclassify non‑native speakers and so cannot be treated as neutral proxies for proficiency or integrity in high‑stakes contexts.
- Apply a transparent, fair scoring framework so decisions are explainable and defensible, using AI primarily as decision support rather than an unchecked arbiter, in line with emerging guidance on skill assessments in the AI age
- Embed and iterate the assessment within real hiring, promotion, and development decisions, much as firms that are deeply committed to AI fluency are beginning to surface AI usage explicitly in performance and talent processes.
Done well, this leads to sharper talent choices, more targeted upskilling, better returns on AI investment, and more equitable outcomes than crude AI detection or ad hoc judgement can provide. Organisations that measure AI proficiency in this deliberate way will be better placed to build resilient, adaptable teams ready for an AI‑pervasive future, and to demonstrate to regulators, boards and employees that their approach to AI is both strategic and responsible, echoing best practice emerging in heavily regulated sectors such as finance.
Frequently Asked Questions (FAQ)
Prompting, verification, workflow design, automation, and responsible AI use.
No. These skills apply across functions, from admin and marketing to finance and operations.
Clear examples of how you used AI to save time, improve quality, or support better decisions.
Begin with your current tasks, test AI on repeat work, and track the results.
Related Articles
 L&D Insights
L&D Insights Tips & Tricks
Tips & TricksCopilot vs. ChatGPT vs. Gemini: How to Choose the Right AI Assistant for Your Task
Microsoft Copilot, OpenAI’s ChatGPT, and Google’s Gemini are leading AI assistants, each excelling in different environments. Copilot integrates deeply with Microsoft 365 to automate documents, data analysis, and email, while ChatGPT shines in open-ended conversation, creative writing, and flexible plugin-driven workflows. Gemini prioritises speed and factual accuracy within Google Workspace, offering powerful research and summarisation capabilities. Choosing the right tool depends on your ecosystem, need for customisation, and whether productivity, creativity, or precision is the top priority.
 L&D Insights
L&D InsightsLiteracy vs Digital Literacy: What Are the Differences?
Traditional reading-and-writing literacy has broadened into digital literacy—the ability to locate, evaluate, create, and communicate information safely and effectively through technology. The article traces this evolution from basic “computer literacy” of the 1990s to today’s multifaceted concept that spans information, media, and AI literacy. Digital skills now underpin social inclusion, workforce readiness, and democratic participation, while gaps in access, competence, and support exacerbate inequality.
